Back to Browse
Free

Server data from the Official MCP Registry
Social-choice voting rules (Borda, Copeland, Condorcet, STV, opinion pool) as MCP tools.
About
Social-choice voting rules (Borda, Copeland, Condorcet, STV, opinion pool) as MCP tools.
Security Report
10.0
Low Risk10.0Low RiskValid MCP server (1 strong, 3 medium validity signals). No known CVEs in dependencies. Package registry verified. Imported from the Official MCP Registry.
12 files analyzed · 1 issue found
Security scores are indicators to help you make informed decisions, not guarantees. Always review permissions before connecting any MCP server.
How to Install
Add this to your MCP configuration file:
{
"mcpServers": {
"io-github-hrishikabra-voting-mcp": {
"args": [
"voting-mcp"
],
"command": "uvx"
}
}
}Documentation
View on GitHubFrom the project's GitHub README.
voting-mcp
Principled social-choice aggregation as MCP tools — with a benchmark that measures the accuracy lift over naive majority vote.
Almost every multi-agent system aggregates votes with Counter(votes).most_common(1), throwing
away preference order and confidence. voting-mcp ships the real rules (Borda, Copeland,
Condorcet, approval, STV, linear opinion pool) as callable MCP tools — each with its known
axiomatic behavior and explicit, documented tie-breaking — plus a reproducible benchmark that
aggregates a diverse ensemble of LLMs on a reasoning set and reports accuracy with bootstrap
confidence intervals.
The server is pure compute: stdio transport, no network, no file writes, no secrets — clean against the OWASP MCP Top 10 by construction.
Install
# run the server directly (once published)
uvx voting-mcp
# or from source
git clone https://github.com/HrishiKabra/voting-mcp && cd voting-mcp
uv sync
uv run python -m voting_mcp.server
Add it to an MCP client (e.g. Claude Desktop claude_desktop_config.json):
{
"mcpServers": {
"voting": { "command": "uvx", "args": ["voting-mcp"] }
}
}
Tools
Every tool takes a profile ({candidates, ballots}) and returns a Result with the full
co-winner set (winners, so ties are never hidden), the single tie-broken winner (or null
when none exists), a ranking, per-candidate scores, and a note.
| Tool | Ballots | Notes |
|---|---|---|
borda | rankings | positional; Condorcet-inconsistent, clone-sensitive |
copeland | rankings | Condorcet-consistent pairwise (+1 win, +0.5 tie) |
condorcet | rankings | returns the pairwise winner or an explicit no-winner on a cycle |
approval | approval sets | most-approved wins |
stv | rankings | single-winner instant-runoff; clone-resistant |
opinion_pool | distributions | linear pool — preserves confidence, not an argmax vote |
plurality | rankings | baseline (most first choices) |
majority | rankings | strict >50% or no winner |
aggregate_rule | any | dispatch by a rule enum |
Tie-breaking is an explicit parameter (lexicographic default, none, or seeded random).
Benchmark
Aggregate an ensemble of 5 models (one OpenAI-compatible client via OpenRouter) on ARC-Challenge and compare each rule to the naive majority vote:
uv sync --extra bench
uv run python -m bench.fetch_arc --limit 200
# prints a cost estimate and STOPS; add --yes to actually call the API, --mock for a free dry run
uv run python -m bench.run_ensemble --dataset bench/datasets/arc_challenge.jsonl --limit 200 --yes
uv run python -m bench.compare --dataset bench/datasets/arc_challenge.jsonl --limit 200
Every raw response is cached under bench/results/raw/; re-runs never re-call the API, so
aggregation tweaks are free.
Results
5-model ensemble (gpt-4o-mini · gemini-2.5-flash-lite · deepseek-v3 · claude-haiku-4.5 ·
glm-4.7), n = 200, bootstrap 95% CI. Two datasets of different difficulty; full write-up and
both plots in RESULTS.md.
MMLU-Pro (hard, baseline 73.5%) — the informative case:
| Rule | Accuracy | 95% CI | paired Δ vs majority | p |
|---|---|---|---|---|
| opinion_pool | 0.755 | [0.695, 0.815] | +0.020 [−0.011, +0.052] | 0.225 |
| majority_vote (baseline) | 0.735 | [0.679, 0.788] | — | — |
| approval | 0.701 | [0.640, 0.757] | −0.035 [−0.063, −0.006] | 0.014 |
| stv | 0.693 | [0.630, 0.750] | −0.043 [−0.072, −0.015] | 0.002 |
| copeland | 0.647 | [0.580, 0.710] | −0.088 [−0.127, −0.052] | <0.001 |
| condorcet | 0.620 | [0.550, 0.685] | −0.115 [−0.155, −0.079] | <0.001 |
| majority (strict) | 0.590 | [0.520, 0.655] | −0.145 [−0.189, −0.105] | <0.001 |
| borda | 0.472 | [0.405, 0.540] | −0.263 [−0.323, −0.206] | <0.001 |
Δ is tested with a paired bootstrap on the per-question accuracy difference (same questions, so shared difficulty cancels), not by eyeballing the independent CIs.
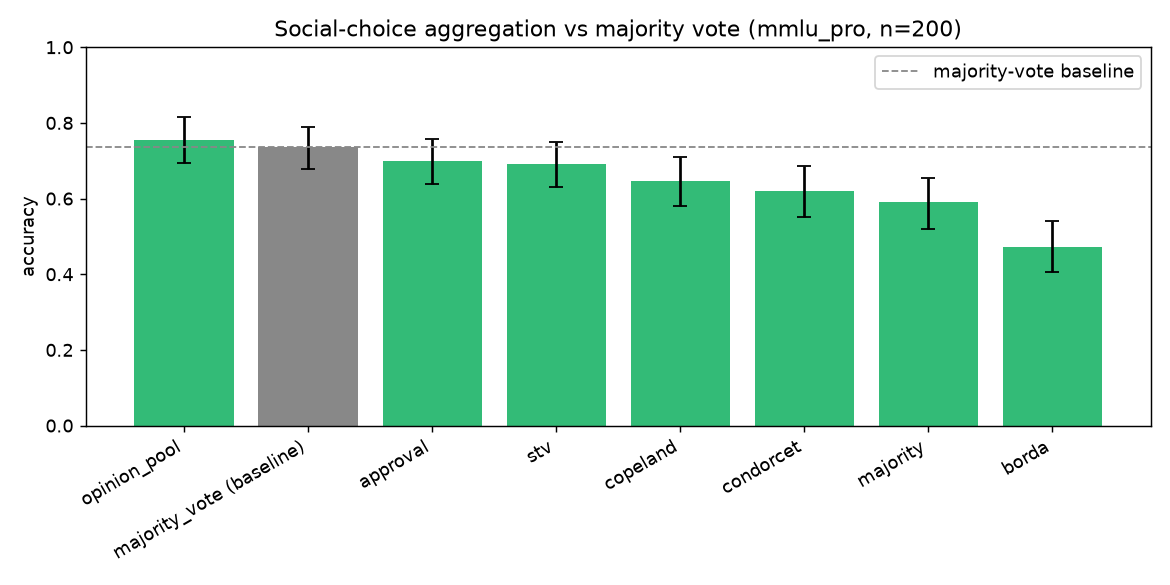
The finding (honest): the value isn't "fancy voting beats majority." It's that the
confidence-preserving rule (opinion_pool) wins when the crowd is uncertain (+2.0pp, the only
rule above baseline — suggestive but not significant at n=200, paired p=0.225), while forcing
the distributions into full rankings actively hurts, significantly — every ranking rule is
below baseline at paired p≤0.014, and borda collapses to 0.472 because with 10 options the
tail of the ranking is mostly noise. Aggregate the confidence; don't throw it away. On
ARC-Challenge (baseline 96.8%, near-ceiling) nothing separates — no rule differs
significantly. See RESULTS.md.
Develop
uv run pytest -q
uv run ruff check .
uv run mypy --strict src
# exercise the tools in the MCP Inspector:
npx @modelcontextprotocol/inspector uv run python -m voting_mcp.server
Note: if you keep this repo under an iCloud-synced folder (e.g.
~/Desktop), iCloud can spawn duplicate.pthfiles that intermittently break the editable install. Tests usepythonpath=src; run the server withPYTHONPATH=srcif an import fails, or move the repo off the synced folder.
Related research
The choice of rules here grows out of the author's work on voting-rule design: Optimizing Voting Rules for Social Welfare and Beyond (AAMAS). That line of work asks which aggregation rules maximize welfare given how voters actually express preferences; this project applies the same lens to LLM ensembles — where the benchmark's answer is that confidence-preserving aggregation (the linear opinion pool) is what pays off, and forcing cardinal beliefs into ordinal rankings destroys signal.
License
MIT
Reviews
No reviews yet
Be the first to review this server!
More Developer Tools MCP Servers
Git
Freeby Modelcontextprotocol · Developer Tools
Read, search, and manipulate Git repositories programmatically
80.0K
Stars
6
Installs
6.5
Security
No ratings yet
Local
Toleno
Freeby Toleno · Developer Tools
Toleno Network MCP Server — Manage your Toleno mining account with Claude AI using natural language.
137
Stars
533
Installs
8.0
Security
4.8
Local
mcp-creator-python
Freeby mcp-marketplace · Developer Tools
Create, build, and publish Python MCP servers to PyPI — conversationally.
-
Stars
80
Installs
10.0
Security
4.6
Local