Back to Browse
Free

Server data from the Official MCP Registry
Local-first AI memory layer with hybrid search. Postgres + pgvector. Self-hosted, MIT.
About
Local-first AI memory layer with hybrid search. Postgres + pgvector. Self-hosted, MIT.
Security Report
10.0
Low Risk10.0Low RiskValid MCP server (1 strong, 5 medium validity signals). No known CVEs in dependencies. Imported from the Official MCP Registry.
8 files analyzed · No issues found
Security scores are indicators to help you make informed decisions, not guarantees. Always review permissions before connecting any MCP server.
Permissions Required
This plugin requests these system permissions. Most are normal for its category.
What You'll Need
Set these up before or after installing:
Hostname of the Postgres+pgvector instance Memory Vault connects to (e.g. 'host.docker.internal' when Postgres runs on the host, 'localhost' when running natively, or the service name when both run in compose)
Environment variable: DB_HOST
Postgres port
Environment variable: DB_PORT
Postgres database name
Environment variable: DB_NAME
Postgres user with read/write access to the memory vault database
Environment variable: DB_USER
Postgres password for DB_USERRequired
Environment variable: DB_PASSWORD
Documentation
View on GitHubFrom the project's GitHub README.
Memory Vault
![]()
The memory database for AI applications. Self-hosted Postgres + pgvector with hybrid search, MCP-native, and a knowledge graph baked in.
Every conversation with Claude or ChatGPT starts from zero. No memory of what you built last week, what decisions you made last month, what problems you've already solved. You either re-explain everything from scratch, or paste in a wall of context and hope it fits in the window.
Memory Vault is the persistent layer underneath. It stores what you want your AI to remember — decisions, conversations, notes, project context — in a single Postgres database with hybrid semantic + keyword search. Claude can recall and store memories during any session via MCP, you can chat with your own memories through a local LLM, or you can build your own AI tool on top of the REST API.
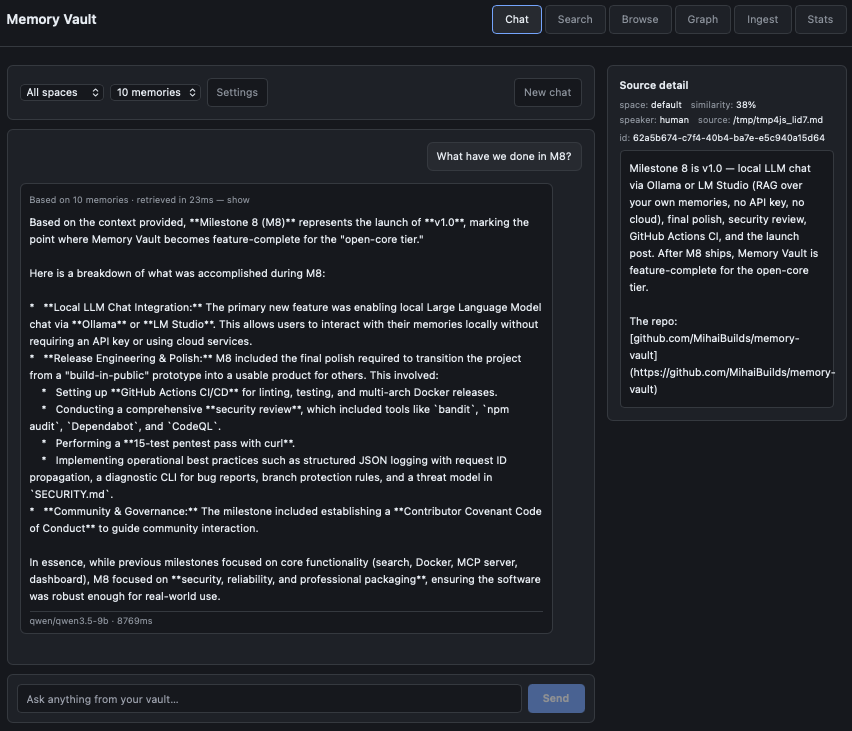
Chat with your vault using a local LLM. Every answer shows the exact memories it was grounded in — click any source to verify.
Status
v1.0 — released 2026-05-07. First stable release of Memory Vault. M1-M7 (hybrid search, Docker, MCP, REST API, dashboard, knowledge graph, local LLM chat) all shipped and stable.
Release notes: GitHub Releases.
Semver from here forward — the public surface (REST API endpoints, MCP tool signatures, DB schema) is stable. Breaking changes only on a major version bump.
Quick Start (Docker)
git clone https://github.com/MihaiBuilds/memory-vault.git
cd memory-vault
docker compose up -d
That's it. PostgreSQL + pgvector + Memory Vault, running and ready. Migrations run automatically on first start.
# Check it's working
docker compose exec app memory-vault status
# Ingest a file
docker compose exec app memory-vault ingest /path/to/file.md --space default
# Search
docker compose exec app memory-vault search "your query here"
Data persists in a Docker volume — docker compose down and up again, your memories are still there.
Open http://localhost:8000 in your browser to use the dashboard (Chat, Search, Browse, Graph, Ingest, Stats).
Windows users: clone into WSL2, not a Windows path, and read docs/windows.md if you hit a line-ending error.
No-Docker quick start
If you prefer running without Docker:
Prerequisites
- Python 3.11+
- PostgreSQL 16 with pgvector extension
Setup
# Clone
git clone https://github.com/MihaiBuilds/memory-vault.git
cd memory-vault
# Create virtual environment
python -m venv .venv
source .venv/bin/activate
# Install dependencies
pip install -e .
# Configure
cp .env.example .env
# Edit .env with your PostgreSQL credentials
# Run migrations
memory-vault migrate
# Verify
memory-vault status
Usage
# Ingest a file
memory-vault ingest notes.md --space default
# Search memories
memory-vault search "hybrid search architecture" --limit 5
# Check status
memory-vault status
Features
- Hybrid search — semantic similarity + keyword matching combined, so you find the right memory even when you don't remember the exact words
- MCP integration — four tools (
recall,remember,forget,memory_status) that Claude can use natively during any session - Local LLM chat — query your own memories through LM Studio without sending anything to the cloud, with sources shown for every answer
- Knowledge graph — entities and relationships extracted automatically, connections between things emerge over time
- Memory spaces — separate namespaces for different projects or domains
- REST API — integrate AI memory into any application
- One-command setup —
docker compose upand it's running - Self-hosted — your data stays on your machine, always
Architecture
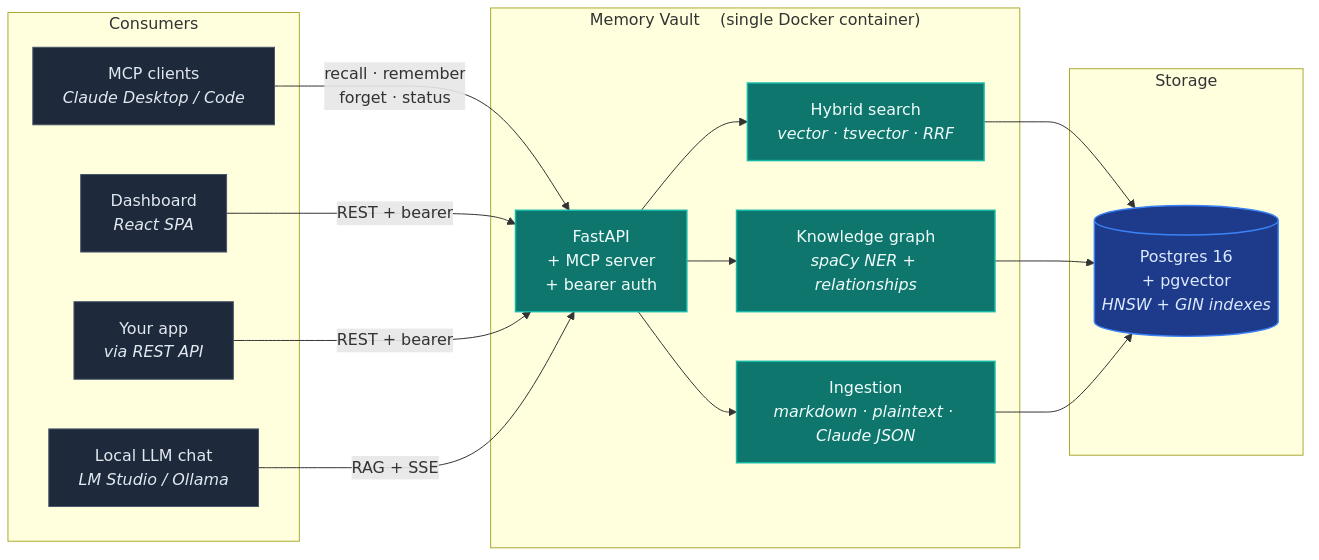
Postgres + pgvector at the core. The same memory layer is reachable from MCP (Claude), the dashboard chat page, the REST API, and any app you build on top.
Three things are deliberate about this stack:
- One database, not two. Vector embeddings, full-text indexes, and relational data all live in Postgres. No separate vector DB to keep in sync.
- Frontend-agnostic. The dashboard is one consumer of the API, not the API itself. MCP, REST, CLI, and your own apps are equal first-class clients.
- CPU-only by default. No GPU required. Embeddings (sentence-transformers) and entity extraction (spaCy) both run on a normal laptop.
Tech Stack
- PostgreSQL 16 + pgvector — vector storage and hybrid search in one database
- Python 3.11+ — async backend with psycopg 3
- sentence-transformers —
all-MiniLM-L6-v2embeddings (384-d, runs on CPU) - spaCy —
en_core_web_smfor entity extraction (CPU-only, no LLM calls) - FastAPI — REST API with bearer auth, rate limiting, and OpenAPI docs
- React 19 + Vite + TanStack Query — web dashboard, baked into the main Docker image
- Cytoscape.js + cose-bilkent — force-directed knowledge graph rendering on the dashboard
- Docker — one-command deployment with
docker compose up - MCP — Claude integration via FastMCP (stdio transport)
MCP Integration (Claude Desktop & Claude Code)
Memory Vault exposes four tools via the Model Context Protocol so Claude can read and write memories during any conversation.
Tools
| Tool | Description |
|---|---|
recall | Search memories with hybrid search (vector + full-text + RRF) |
remember | Store a new memory — auto-classified and embedded |
forget | Soft-delete a memory by chunk ID |
memory_status | Database health, chunk counts, embedding model info |
Resources
| Resource | Description |
|---|---|
memory://spaces | List all memory spaces with chunk counts |
memory://stats | Current system statistics |
Setup — Claude Code
Add to your project's .mcp.json:
{
"mcpServers": {
"memory-vault": {
"command": "python",
"args": ["-m", "src.mcp"],
"cwd": "/path/to/memory-vault",
"env": {
"PYTHONPATH": "/path/to/memory-vault",
"DB_HOST": "localhost",
"DB_PORT": "5432",
"DB_NAME": "memory_vault",
"DB_USER": "memory_vault",
"DB_PASSWORD": "memory_vault"
}
}
}
}
Setup — Claude Desktop
Add the same config to Claude Desktop's settings (Settings → Developer → Edit Config). The server runs over stdio — no HTTP, no ports to expose.
Docker Users
If you're running Memory Vault via Docker, point DB_HOST at the Docker host:
{
"mcpServers": {
"memory-vault": {
"command": "python",
"args": ["-m", "src.mcp"],
"cwd": "/path/to/memory-vault",
"env": {
"PYTHONPATH": "/path/to/memory-vault",
"DB_HOST": "127.0.0.1",
"DB_PORT": "5432",
"DB_NAME": "memory_vault",
"DB_USER": "memory_vault",
"DB_PASSWORD": "memory_vault"
}
}
}
}
The MCP server itself runs on the host (not inside Docker) and connects to the PostgreSQL container. Make sure port 5432 is exposed in your
docker-compose.yml.
Verify It Works
Once configured, Claude will have access to the memory tools. Try:
"Use memory_status to check the memory system."
"Remember that we chose Redis for the session cache."
"Recall everything about hybrid search."
Local LLM Chat
Memory Vault includes a chat page that lets you talk to your own memories using a local LLM — no cloud, no OpenAI key, no telemetry. The dashboard runs hybrid search against your vault, builds a context block from the top hits, and streams the answer back from a model running on your machine.
Sources are shown with every answer. Every response includes the exact chunks the LLM used, with similarity scores and content previews. Click any source to verify the answer is grounded in your data, not invented. This is the differentiator vs. opaque chat-over-docs tools — you always know what the model saw.
Setup
Memory Vault uses LM Studio as the local LLM provider in v1.0.
- Download and install LM Studio.
- Load a non-thinking model — Qwen2.5 (7B+), Llama 3 (8B+), or similar. Avoid Qwen3, DeepSeek-R1, and o1-style reasoning models — they emit chain-of-thought into the answer and break the RAG flow.
- Start the local server (LM Studio → Developer tab → Start Server). Default address:
http://localhost:1234. - Open the Memory Vault dashboard → Chat page → ⚙️ Settings → confirm the Local LLM URL points at your LM Studio instance. The model is auto-detected.
That's it. Ask a question; the dashboard retrieves relevant chunks, sends them with your question to LM Studio, and streams the answer back.
How it works
- Hybrid search retrieves the top chunks for your question (same engine as
/api/searchand MCPrecall) - Top hits are packed into a 6,000-token context budget — oldest history dropped first, then lowest-similarity chunks
- LM Studio generates an answer streamed token-by-token via Server-Sent Events
- Sources arrive first in the stream, so the UI shows "based on N memories" before tokens start flowing
Why LM Studio first
LM Studio's native API supports reasoning="off", which is the only reliable way to suppress chain-of-thought from thinking models in a RAG flow. Memory Vault uses the native API by default and falls back to OpenAI-compat (/v1/chat/completions) with <think>...</think> stripping if the native API isn't available.
REST API
Every MCP tool is also exposed as an HTTP endpoint so you can integrate Memory Vault into any app, script, or language. The API is served by FastAPI at http://localhost:8000 when you run docker compose up.
- Interactive docs: http://localhost:8000/docs
- OpenAPI schema: http://localhost:8000/openapi.json
The auto-generated /docs page is the canonical API reference — it stays in sync with the code. The summary below is for orientation.
Authentication
All endpoints except /api/health require a bearer token. Create one via the CLI:
docker compose exec app memory-vault token create my-app
The plaintext token is shown once — copy it immediately. Then send it as a header:
curl -H "Authorization: Bearer mv_..." http://localhost:8000/api/spaces
Manage tokens:
memory-vault token list
memory-vault token revoke mv_abc1234
To disable auth entirely (local dev only), set API_AUTH_ENABLED=false.
Endpoints
| Method | Path | Description |
|---|---|---|
GET | /api/health | Service + database health (no auth) |
GET | /api/spaces | List memory spaces with chunk counts |
POST | /api/search | Hybrid search (vector + full-text + RRF) |
GET | /api/chunks | List chunks with pagination and filters |
GET | /api/chunks/{id} | Get a single chunk |
DELETE | /api/chunks/{id} | Soft-delete (forget) a chunk |
POST | /api/ingest/text | Ingest a text string as a chunk |
POST | /api/ingest/file | Upload a file through the ingestion pipeline |
POST | /api/chat | RAG chat over hybrid search (non-streaming) |
POST | /api/chat/stream | RAG chat with token-by-token SSE streaming |
Example — search
curl -X POST http://localhost:8000/api/search \
-H "Authorization: Bearer $MV_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"query": "how does hybrid search work",
"spaces": ["default"],
"limit": 5
}'
Example — ingest text
curl -X POST http://localhost:8000/api/ingest/text \
-H "Authorization: Bearer $MV_TOKEN" \
-H "Content-Type: application/json" \
-d '{"text": "Decided to use RRF for hybrid merging", "space": "default"}'
Example — upload a file
curl -X POST http://localhost:8000/api/ingest/file \
-H "Authorization: Bearer $MV_TOKEN" \
-F "file=@notes.md" \
-F "space=default"
Configuration
| Variable | Default | Description |
|---|---|---|
API_HOST | 0.0.0.0 | Bind address |
API_PORT | 8000 | Port |
API_AUTH_ENABLED | true | Set false to disable bearer auth (local dev only) |
API_CORS_ORIGINS | * | Comma-separated allowed origins, or * |
API_RATE_LIMIT_PER_MIN | 120 | Per-IP request limit per minute |
Dashboard
Memory Vault ships with a web UI baked into the same Docker image as the API — no separate deploy, no extra port. Open http://localhost:8000 in your browser after docker compose up.
Six pages:
- Chat — talk to your vault with a local LLM, sources shown for every answer (default landing page)
- Search — hybrid search with space filter, similarity scores, expandable hit content
- Browse — paginated chunk list with space + sort filters, two-step inline delete
- Graph — force-directed knowledge graph (Cytoscape.js), pan/zoom, click a node to see its mentions and related entities, filters for space / type / min-mentions / max-nodes
- Ingest — paste text or upload files (one at a time in v1.0), per-file status, batch summary
- Stats — system health, total chunks, spaces table with visual distribution, auto-refresh every 30s
Access
The dashboard uses the same bearer token as the API. Create one and paste it into the dashboard's token screen:
docker compose exec app memory-vault token create dashboard
The plaintext token is shown once — copy it immediately. Open http://localhost:8000, paste into the prompt, and the dashboard stores it in localStorage under memory-vault-token. You won't be asked again on that browser.
Rotating or revoking
# See which tokens exist
docker compose exec app memory-vault token list
# Revoke by prefix (shown in list output)
docker compose exec app memory-vault token revoke mv_abc1234
# Create a new one
docker compose exec app memory-vault token create dashboard
After revoking, the dashboard will hit a 401 on its next request and auto-clear the stored token, forcing you to paste the new one.
Troubleshooting
- Prompted for token every reload: your browser is blocking
localStorage(private mode, strict cookie settings). Use a normal window or allow storage forlocalhost. - 401 on every request: the token was revoked or
API_AUTH_ENABLEDchanged. Create a fresh token and paste it in. - Dashboard shows but API calls fail with CORS: you're hitting the API on a different origin than the dashboard. The baked-in build avoids this — use
http://localhost:8000, not the dev server, unless you know what you're doing. - Running the dev server:
cd web && npm install && npm run devserves the UI athttp://localhost:5173with API calls proxied to:8000. For development only. - Windows-specific issues: see docs/windows.md.
- Reporting a bug: run
docker compose exec app memory-vault diagnose(ormemory-vault diagnoseon the host for a fuller bundle includingdocker compose ps+ db logs). The command writes amemory-vault-diagnostic-YYYY-MM-DD-HHMMSS.zipcontaining app logs, status, OS info, and redacted env vars. Bearer tokens, passwords, andmv_tokens are auto-scrubbed — but please review the bundle before attaching it to a public GitHub issue. - Quoting a request ID: every API response carries an
X-Request-IDheader (UUID hex). Include it in bug reports — it lets the maintainer grep the same request across the structured JSON logs.
How It Works
Hybrid Search
Memory Vault combines two search methods and merges the results:
- Vector search — converts your query to an embedding, finds semantically similar chunks via HNSW index
- Full-text search — keyword matching via PostgreSQL tsvector + GIN index
- RRF merging — Reciprocal Rank Fusion combines both ranked lists so neither method dominates
This means you find the right memory whether you remember the exact words or just the concept.
Query Enrichment
Before searching, Memory Vault generates up to 3 query variations using the embedding model's WordPiece tokenizer to extract key technical terms. This improves recall without losing precision.
Ingestion Pipeline
Async queue-based pipeline with adapters for different input formats:
- Markdown — splits by headings, preserves structure
- Plain text — paragraph-based with smart merging
- Claude JSON — parses Claude conversation exports
Knowledge Graph
Memory Vault extracts entities and relationships from every ingested chunk and stores them alongside your memories. Click the Graph page in the dashboard to see how the things you've stored connect to each other.
How extraction works:
- spaCy NER — the small
en_core_web_smmodel (~15 MB, CPU-only) tagsPERSON,ORG, andPRODUCTentities, mapped to Person, Project, and Tool respectively. - Concept extraction — multi-token noun phrases that appear at least twice within a chunk become Concept entities. No LLM, no API calls.
- Co-occurrence relationships — any two entities found in the same chunk produce a
related_torelationship. Edge weight grows with co-occurrence count across chunks. - Per-space deduplication — entities are deduplicated by
(lower(name), type, space), so the same entity stays one node within a space without merging across unrelated projects.
The whole pipeline runs synchronously on ingest, on the same CPU that runs the embeddings — no extra services, no external API costs.
These trade-offs are deliberate. spaCy + co-occurrence is fast, free, and gets you 80% of the way to a useful graph at 0% of the LLM cost. The honest gaps are documented in the Limitations section below.
Performance Tuning
Memory Vault ships with maintenance_work_mem = 1 GB as the default in the bundled docker-compose.yml. The stock PostgreSQL default is 64 MB, which makes HNSW index builds on pgvector painfully slow once your corpus grows past a few thousand chunks.
If you're running on a host with 16 GB of RAM or more, bumping this to 2 GB gives noticeably faster index rebuilds with no downside. Edit the command: block in docker-compose.yml:
db:
image: pgvector/pgvector:pg16
command:
- postgres
- -c
- maintenance_work_mem=2GB
If you're running on a small box (4 GB total RAM or less, e.g. a tiny VPS), you may want to drop this back down to 256 MB so the rest of the system has breathing room. Memory Vault still works at the stock 64 MB default — it's just slower on large index rebuilds.
Limitations
v1.0 limitations (honest)
- English-only NER.
en_core_web_smis English-trained; non-English text gets little to no useful entity extraction. Hybrid search and chat work fine in any language — only the auto-extracted knowledge graph is English-limited. - NER is context-dependent. spaCy decides PERSON vs. ORG based on the surrounding sentence. The same name can land as both Person and Project entities depending on syntactic role.
- No fuzzy entity matching. "PostgreSQL" and "Postgres" are separate entities. No alias merging in v1.0.
- No re-extraction on edit. If you forget a chunk and re-ingest a corrected version, the new entities are added; the old ones aren't cleaned up automatically.
- Single-instance. No multi-user / multi-tenant. One vault per deployment. Team features are PRO.
- LM Studio only for chat. No Ollama provider in v1.0.
PRO tier (planned)
Team features, advanced analytics, hosted tier. The free / open-source core stays free forever — open-core, not bait-and-switch.
FAQ
How is this different from claude-mem / cognee / Mem0?
Different layer of the stack. Filesystem-based tools (claude-mem, claudesidian, obsidian-second-brain) keep markdown notes on disk and use grep/read at retrieval time. They work great until your vault grows past a few thousand notes — then grep gets slow and semantic recall isn't there. Memory Vault is a database-backed memory layer (Postgres + pgvector + tsvector + RRF) designed to scale and to be built on top of. Frontend-agnostic. Use it through MCP, REST, the dashboard, or your own app — all equal first-class clients.
cognee and Mem0 are closer in stack but cloud-first or SDK-first. Memory Vault is self-hosted infrastructure-first.
Do I need a GPU?
No. Default embeddings (all-MiniLM-L6-v2, 384-d) and entity extraction (en_core_web_sm) both run on CPU. Local LLM chat uses LM Studio on whatever hardware you have — a modern 16 GB-RAM machine handles 7B-parameter models comfortably.
Is my data sent to the cloud?
No. Memory Vault is self-hosted end-to-end. Embeddings are local (sentence-transformers), entity extraction is local (spaCy), chat uses your local LM Studio instance. No telemetry, no API calls to OpenAI / Anthropic / anyone. Your data stays on your machine, period.
Can I use it without Claude?
Yes. The MCP integration is one of three interfaces. The REST API and dashboard work standalone. Use the chat page with any local LLM (LM Studio supports many open-weights models), or build your own AI tool on top of the API.
What languages does NER support?
English only in v1.0. The default spaCy model is English-trained — non-English text gets little to no useful entity extraction. No multilingual NER in v1.0. Hybrid search and chat work fine in any language; only the auto-extracted knowledge graph is English-limited.
How much disk and RAM does it need?
Roughly: 2 GB disk (Docker image + Postgres data + spaCy + embedding model), 1-2 GB RAM idle, 4 GB+ recommended for active use. The bundled config sets maintenance_work_mem=1GB for fast HNSW index builds — drop it to 256 MB on a small VPS.
Can I run multiple Memory Vault instances?
Yes. Each instance is a single docker compose up. Use separate compose project names (docker compose -p mv-personal up, docker compose -p mv-work up) to keep them isolated, or clone into separate directories.
What happens to my data on future updates?
Migrations are versioned and forward-only. docker compose pull && docker compose up -d runs new migrations on start. Schema changes will be additive within v1.x — no destructive migrations on a minor version bump. That's part of the v1.x semver promise.
Contributing
Memory Vault is MIT-licensed and PRs are welcome. See:
- CONTRIBUTING.md — how to report bugs, suggest features, set up dev environment, coding conventions
- CODE_OF_CONDUCT.md — Contributor Covenant v2.1
- SECURITY.md — reporting vulnerabilities (email
support@mihaibuilds.com, don't open public issues) - Bug report template — includes
memory-vault diagnoseinstructions - Feature request template — frame the problem before suggesting a solution
Single-maintainer project. PRs are reviewed when I have time. Big features should be discussed in an issue first.
License
The core is MIT licensed — free forever. Everything that makes Memory Vault useful as a personal memory system (hybrid search, MCP integration, knowledge graph, dashboard, local LLM chat, Docker setup) will always be free and open source.
A PRO tier for teams and advanced features is planned.
Credits
- @rivestack — Postgres + pgvector tuning tips that landed in v1.0 (
maintenance_work_mem=1GBfor fast HNSW builds). More of his suggestions are on the list. - Beta testers — the people who cloned, broke, and reported things during M1-M7
- The open source giants this is built on — PostgreSQL, pgvector, sentence-transformers, spaCy, FastAPI, FastMCP, React, Cytoscape.js
Follow the Build
- Website: mihaibuilds.com
- Blog: mihaibuilds.com/blog
- GitHub: @MihaiBuilds
- X: @mihaibuilds
Watch the repo to follow along.
Reviews
No reviews yet
Be the first to review this server!
More Security MCP Servers
Toleno
Freeby Toleno · Developer Tools
Toleno Network MCP Server — Manage your Toleno mining account with Claude AI using natural language.
137
Stars
533
Installs
8.0
Security
4.8
Local
mcp-creator-python
Freeby mcp-marketplace · Developer Tools
Create, build, and publish Python MCP servers to PyPI — conversationally.
-
Stars
80
Installs
10.0
Security
4.6
Local
MarkItDown
Freeby Microsoft · Content & Media
Convert files (PDF, Word, Excel, images, audio) to Markdown for LLM consumption
156.1K
Stars
45
Installs
6.0
Security
5.0
Local